






I. Introduction▲
Le format HDF5 (pour Hierarchical Data Format, V5) est un format de type conteneur de fichier. Ce format est donc assimilable à une arborescence de dossiers/fichiers, le tout contenu dans un fichier.
Son histoire commence en 1987, et il s'appelait alors AEHOO (All Encompassing Hierarchical Object Oriented Format). La première version réellement exploitable a vu le jour par l'intervention de la Nasa qui le sélectionne pour son projet EOS (Earth Observing System).
Le projet est alors renommé et le format HDF4 fait son apparition. Cependant, sa structure complexe et certaines limitations de fonctionnement (taille de fichier maximale à 2 Go) vont entraîner la création du format HDF5, simplifiant sa structure et passant outre les limitations bloquantes.
Les possibilités qu'offre le format HDF pour effectuer des calculs complexes sur de grandes masses de données, grâce à une indexation efficace, sont à la base de son succès. De plus, en Python, l'utilisation de ce format est très simple grâce au package h5py.
Pour cet article, seuls seront considérés HDF5 et Python3.x. Le format HDF4 et HDF5 sont non compatibles.
II. Le format HDF5 : la théorie▲
II-A. Les objets▲
Le format HDF5 supporte principalement trois types d'objets. Il est assez limité à ce niveau. Cependant, cela suffit pour la plupart des traitements numériques.
II-A-1. Groupe▲
Les groupes, comme leurs noms l'indiquent, permettent de regrouper des datasets et des attributs, ainsi que des sous-groupes. Il sont assimilables à des dossiers.
Un groupe est constitué :
- d'une liste d'attributs ;
- d'une liste d'objets HDF5 (les groupes étant eux-mêmes de objets HDF5).
II-A-2. Dataset▲
Les datasets sont des tableaux multidimensionnels contenant des données d'un même type. Il sont assimilables à des fichiers.
Un dataset est composé :
- d'un datatype (le type de données stockées) ;
- d'un dataspace (nombre de dimensions du dataset) ;
- d'un format de stockage (linéaire, ou fractionné en morceaux de même dimension).
II-A-3. Attribut▲
Les attributs, enfin, sont assimilables à des métadonnées pour les fichiers ou les dossiers. Fonctionnant sur le principe d'une valeur associée à un nom, ils permettent d'ajouter des descriptions complémentaires ou de stocker de très petites valeurs.
Ils sont constitués :
- d'une valeur ;
- d'un datatype.
II-B. Les types possibles▲
Si la quantité d'objets supportée par HDF5 est limitée, il n'en est pas de même pour les types de données possibles, lesquels permettent de couvrir l'ensemble des besoins scientifiques.
NumPy permet une meilleure intégration de HDF5 dans Python. Cela impose néanmoins que l'on convertisse nos données Python en format NumPy. Afin d'y voir plus clair, voici quelques petits tableaux récapitulatifs :
|
Groupe et dataset |
||
|
Type Python |
Type NumPy |
Objet |
|
bool |
np.bool_ |
dataset |
|
None |
np.float_ |
|
|
int |
np.int_ |
|
|
long |
np.int_ |
|
|
float |
np.float_ |
|
|
complex |
no.complex_ |
|
|
str |
np.str_ |
|
|
bytes |
np.bytes_ |
|
|
bytearray |
np.object_ |
|
|
list |
np.object_ |
|
|
tuple |
np.object_ |
|
|
set |
np.object_ |
|
|
dict |
groupe |
|
Dans le cas des dictionnaires, toutes les clés doivent être de type « str », sans caractères « / » ou « \x00 ».
|
Attributs |
|
|
Type Python |
Type NumPy |
|
bool |
np.bool_ |
|
None |
np.float_ |
|
int |
np.int_ |
|
long |
np.int_ |
|
float |
np.float_ |
|
complex |
no.complex_ |
|
str |
np.uint_ ou np.str_ |
|
bytes |
np.bytes_ |
|
bytearray |
np.object_ |
|
list |
np.object_ |
|
tuple |
np.object_ |
|
set |
np.object_ |
III. Manipulations▲
Comme nous allons le voir, l'accès à un niveau désiré de données doit passer par la transmission d'un pseudo-XPATH. La racine du fichier est alors, comme sous Linux, représentée par « / ».
III-A. Ouvrir un fichier HDF5▲
Pour ouvrir un fichier HDF5, afin d'y lire/modifier des données, le plus simple reste de passer par le logiciel VITABLES.
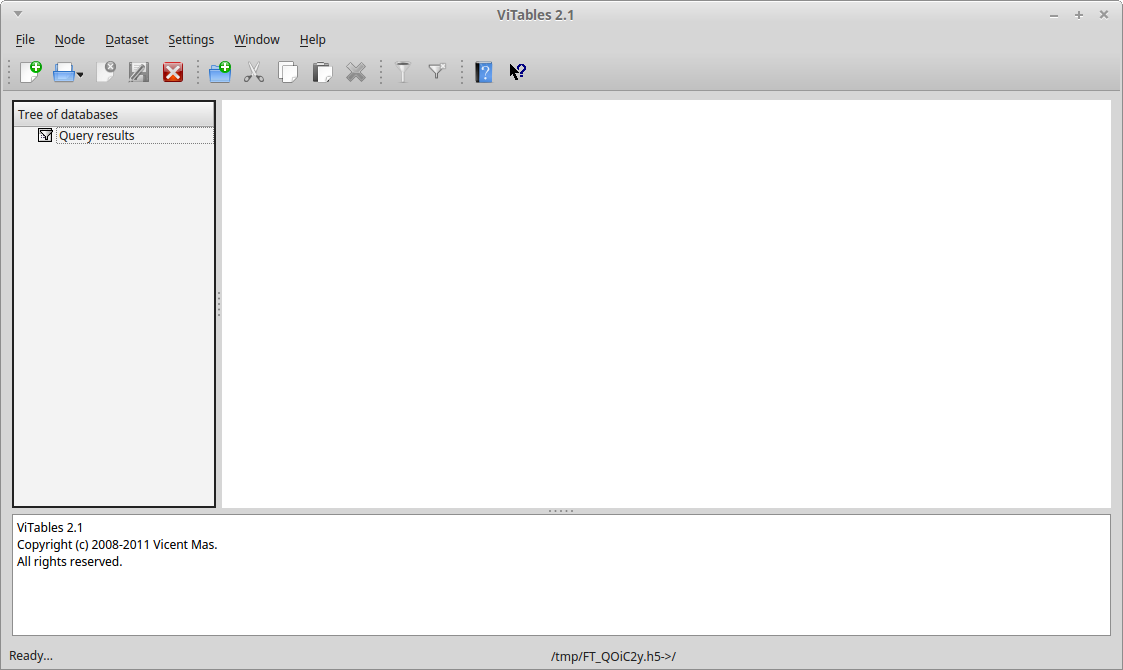
Il s'agit d'un logiciel écrit en Python et PyQt, multiplateforme, créé en 2008. Il vous permettra de visualiser, sous forme de tableau, l'ensemble des données disponibles dans le fichier et de les éditer de façon conviviale.
Ajoutons enfin que VITABLES est directement disponible sur Pypi.
III-B. Fichier▲
III-B-1. Ouverture▲
Lorsque l'on charge un fichier HDF5, nous devons lui passer deux paramètres :
- le chemin d'accès au fichier ;
- le mode d'accès.
Les mode d'accès disponibles sont les suivants :
|
Mode d'accès |
Description |
|
r |
Lecture seule, le fichier doit exister |
|
r+ |
Lecture et écriture, le fichier doit exister |
|
w |
Crée le fichier, écrase si le fichier existe |
|
x |
Crée le fichier, échoue si le fichier existe |
|
a |
Lecture et écriture, crée le fichier s'il n'existe pas |
Ainsi, par exemple, pour ouvrir un fichier en lecture/écriture avec création si inexistant, nous ferons :
2.
3.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')

III-B-2. Forcer l'enregistrement▲
Un des défauts de cette librairie, ou peut-être est-ce du format, est que l'enregistrement des manipulations n'est pas systématiquement effectué dans le fichier.
De fait, vous pourrez constater l'enregistrement :
- directement après la manipulation ;
- à la fermeture du fichier ;
- si vous le demandez expressément.
Pour cette dernière solution, rien de plus simple, il suffit d'utiliser la méthode « flush ».
2.
3.
4.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mon_fichier.flush()
Cette commande permet de demander l'exécution des actions encore non effectives.
III-B-3. Fermeture▲
2.
3.
4.
5.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mon_fichier.flush()
mon_fichier.close()
III-C. Groupe▲
L'ajout ou la suppression d'un groupe est soumis à la condition que le fichier HDF5 soit manipulé dans un mode d'accès autorisant l'écriture.
Si vous essayez de créer un groupe déjà existant, selon le mode d'accès sélectionné, une erreur pourrait survenir
III-C-1. Ajout▲
Pour créer un groupe, il suffit d'appeler la fonction « create_group », puis de lui passer le chemin d'accès :
2.
3.
4.
5.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mon_groupe_01 = mon_fichier.create_group('groupe_01')
mon_fichier.close()
Il est également ensuite possible de créer un ou plusieurs sous-groupes, selon vos besoins :
2.
3.
4.
5.
6.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mon_groupe_01 = mon_fichier.create_group('groupe_01')
mon_sous_groupe_01 = mon_fichier.create_group('/groupe_01/sous_groupe_01')
mon_fichier.close()
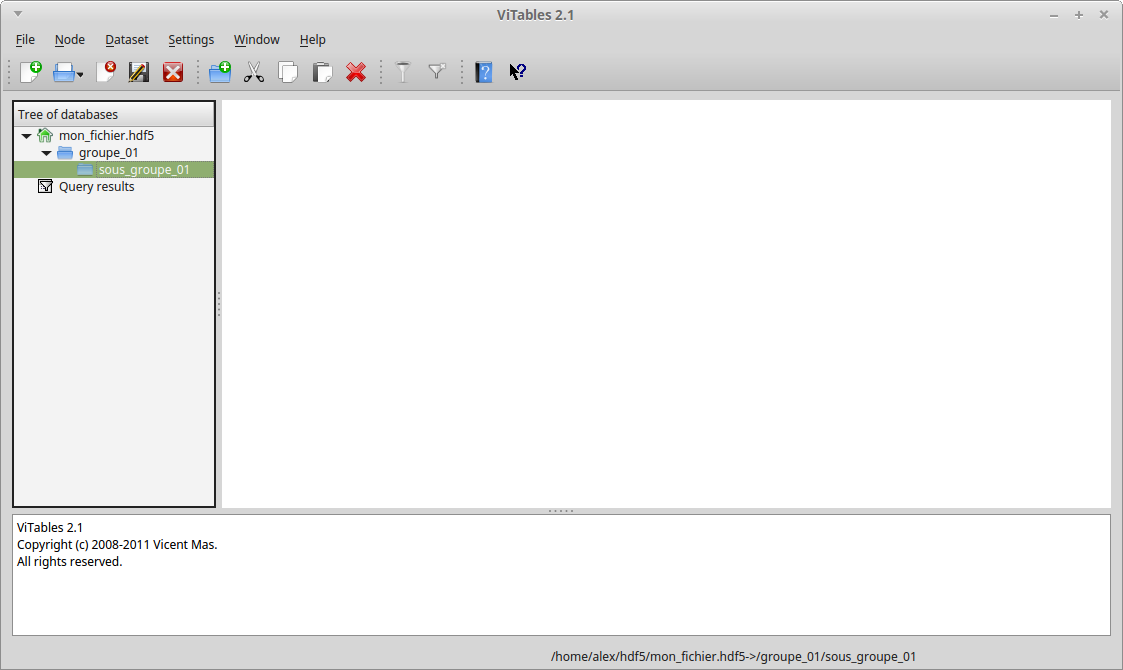
Notons enfin qu'il est possible de tout réaliser en une fois, en utilisant un chemin. Ainsi, les deux lignes précédentes auraient pu être remplacées par la ligne suivante :
2.
3.
4.
5.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mes_groupes_01 = mon_fichier.create_group('/groupe_01/sous_groupe_01')
mon_fichier.close()
III-C-2. Accès▲
Une liaison vers un groupe se fait très simplement de la façon suivante :
tmp_var = mon_fichier['/groupe_01/sous_groupe_01']
Bien entendu, vous pouvez également accéder à un attribut du groupe, de la même façon que vu précédemment avec le chemin d'accès.
De même, vous pouvez avoir aisément accès aux éléments disponibles dans le groupe :
2.
3.
4.
5.
6.
7.
8.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
for element in mon_fichier['/groupe_01'].items():
print(element[0])
print(element[1])
print(element[1].name)
mon_fichier.close()
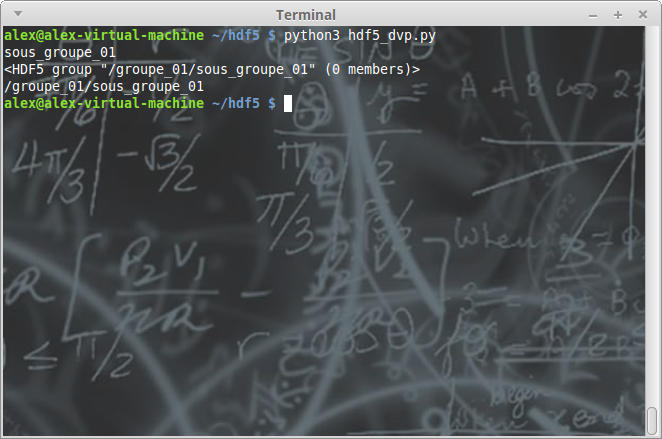
III-C-3. Suppression▲
La suppression, elle aussi est très simple et se réalise de la façon suivante :
2.
3.
4.
5.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
del mon_fichier['/groupe_01/sous_groupe_01']
mon_fichier.close()
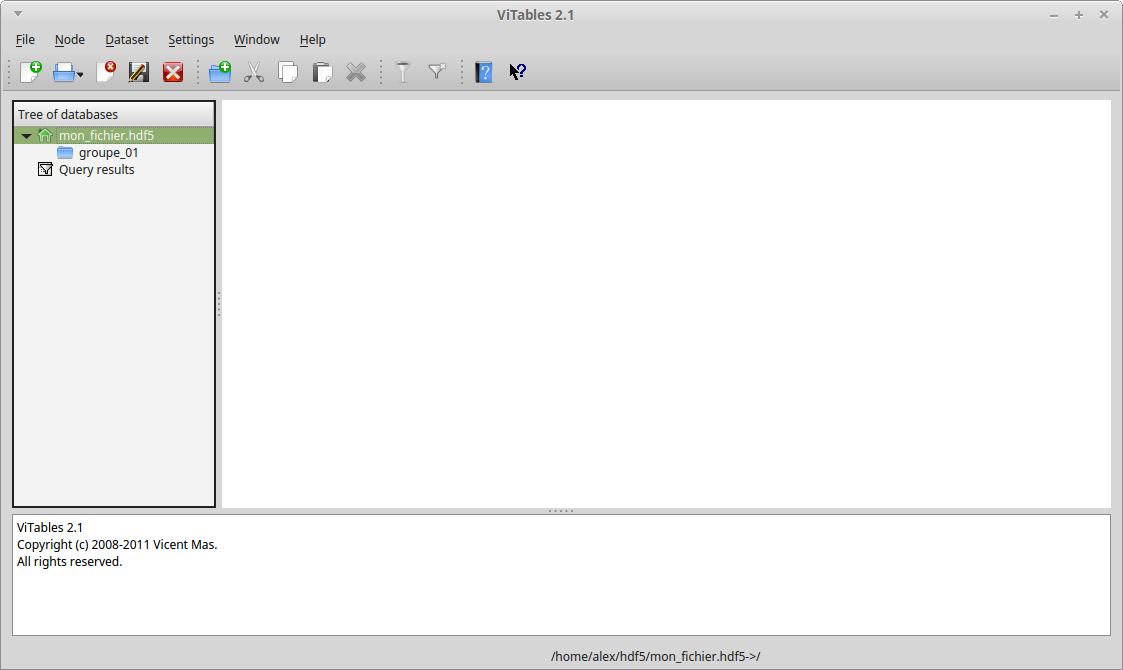
III-C-4. Connaître le chemin d'accès▲
Afin de connaître le chemin d'accès associé à un objet, il suffit d'accéder à l'attribut par défaut « name » :
2.
3.
4.
5.
6.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
mes_groupes_01 = mon_fichier.create_group('/groupe_01/sous_groupe_01')
print(mes_groupes_01.name)
mon_fichier.close()

III-D. Dataset▲
L'ajout ou la suppression d'un dataset est soumis à la condition que le fichier HDF5 soit manipulé dans un mode d'accès autorisant l'écriture.
III-D-1. Ajout / modification▲
Un dataset est assimilable à une matrice NumPy. Pour en créer un, il suffit de passer par la méthode « create_dataset » d'un groupe.
2.
3.
4.
5.
6.
7.
8.
import h5py
import numpy as np
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
groupe_01 = mon_fichier['/groupe_01']
ma_matrice = np.ones((100, 100))
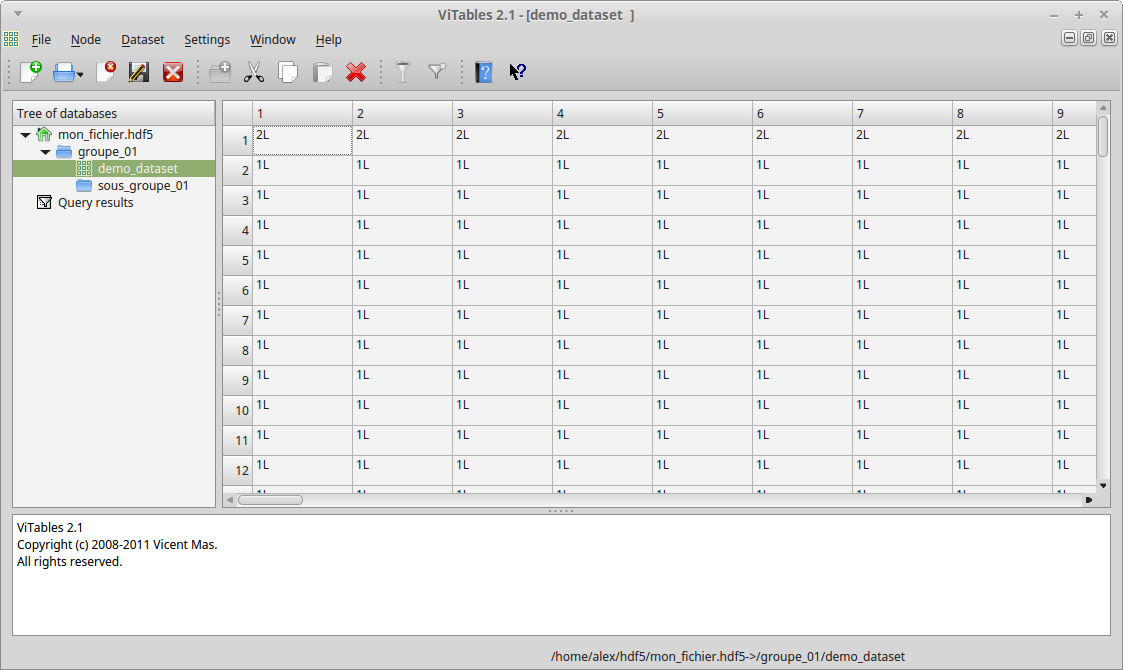
mon_dataset = groupe_01.create_dataset(name='demo_dataset', data=ma_matrice, dtype="i8")
mon_fichier.close()
Par la suite, la syntaxe NumPy est de mise afin de faciliter la manipulation des données.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
import h5py
import numpy as np
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
groupe_01 = mon_fichier['/groupe_01']
ma_matrice = np.ones((100, 100))
mon_dataset = groupe_01['demo_dataset']
print(mon_dataset[0,0])
print(mon_dataset[0, 1:10])
print(mon_dataset[:,::2])
mon_fichier.close()
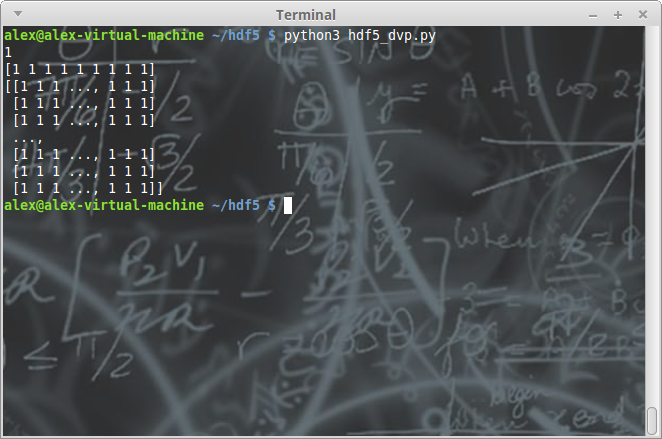
Et bien entendu, une mise à jour est extrêmement simple également :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
import h5py
import numpy as np
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
groupe_01 = mon_fichier['/groupe_01']
ma_matrice = np.ones((100, 100))
mon_dataset = groupe_01['demo_dataset']
mon_dataset[0, :] = 2
print(mon_dataset[0,0])
print(mon_dataset[0, 1:10])
print(mon_dataset[:,::2])
mon_fichier.close()

III-D-2. Accès▲
Accéder à un dataset est relativement simple. Il suffit tout d'abord d'avoir accès au fichier ou au groupe dans lequel se trouve le dataset. Ensuite on y accède comme avec un dictionnaire, où le nom du dataset est en réalité la clé.
mon_dataset = mon_fichier['demo_dataset']
Mais comment connaître la liste des datasets disponibles ? Cela est possible en deux étapes. Tout d'abord, établir la liste des éléments (groupes et datasets) disponibles, puis distinguer les deux types (l'exemple ci-après cherche les éléments à la racine du fichier).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
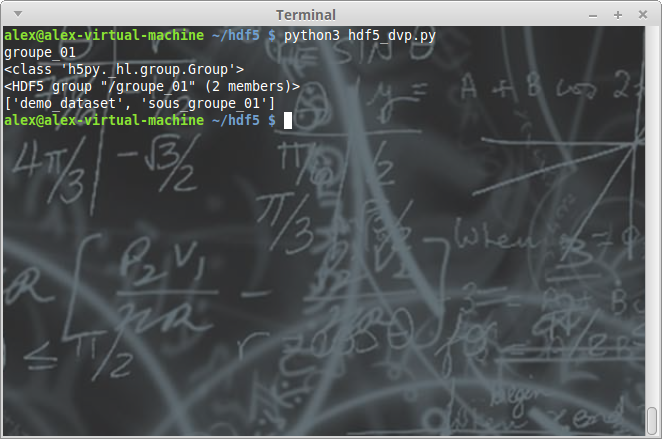
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
list_elmts = [key for key in mon_fichier['/'].keys()]
for key in list_elmts:
print(key)
print(type(mon_fichier['/'][key]))
print(mon_fichier['/'][key])
print([key for key in mon_fichier['/'][key].keys()])
mon_fichier.close()
On peut voir ici que l'on retrouve un groupe et un dataset.
III-D-3. Suppression▲
La suppression s'effectue comme avec un dictionnaire.
2.
3.
4.
5.
6.
7.
8.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
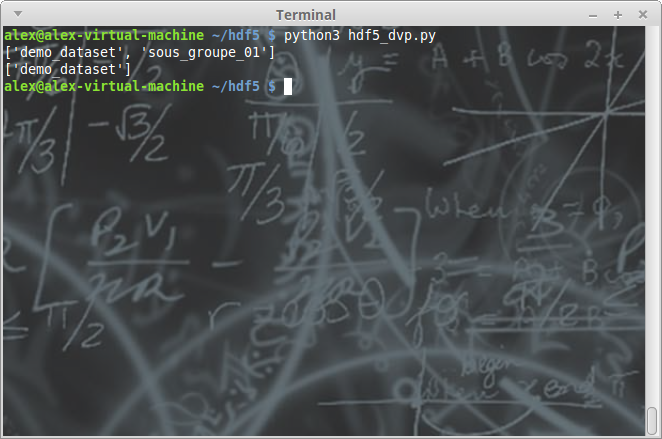
print([key for key in mon_fichier['/']['groupe_01'].keys()])
del mon_fichier['/groupe_01/sous_groupe_01']
print([key for key in mon_fichier['/']['groupe_01'].keys()])
mon_fichier.close()
III-E. Attribut▲
L'ajout ou la suppression d'un attribut est soumis à la condition que le fichier HDF5 soit manipulé dans un mode d'accès autorisant l'écriture.
Dans h5py, les attributs sont disponibles sous la forme d'un dictionnaires « attrs », rattaché à un groupe ou à un dataset.
III-E-1. Ajout / modification▲
L'ajout d'attributs utilise la méthode « create() ». Cependant attention, car si cette méthode permet de créer des attributs, dans le cas où l'attribut existe déjà, il sera écrasé. À utiliser avec précaution donc.
Cette méthode attend quatre paramètres :
|
Paramètres |
Valeur par défaut |
Description |
|
name |
Chaîne de caractères correspondant au nom de l'attribut |
|
|
data |
Il s'agit de la valeur de l'attribut |
|
|
shape |
None |
De type data.shape, il s'agit d'un « tuple » correspondant aux dimensions de l'attribut |
|
dtype |
None |
Il s'agit du type de l'attribut. Dans les faits il s'agira d'un « dtype » de NumPy (np.int32, np.float64, np.dtype(float)…) |
Le paramètre « data » pourra être directement une valeur simple (12, 42.3, 'Hello'…) ou alors un tableau numpy de données (numpy.array(data)). Dans le premier cas, il vous faudra laisser le paramètre « shape » à « None ». Dans le second cas, il vous faudra renseigner correctement ce paramètre. La plupart du temps vous n'aurez même pas besoin de renseigner « shape » et « dtype ».
2.
3.
4.
5.
6.
7.
import h5py
import numpy as np
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
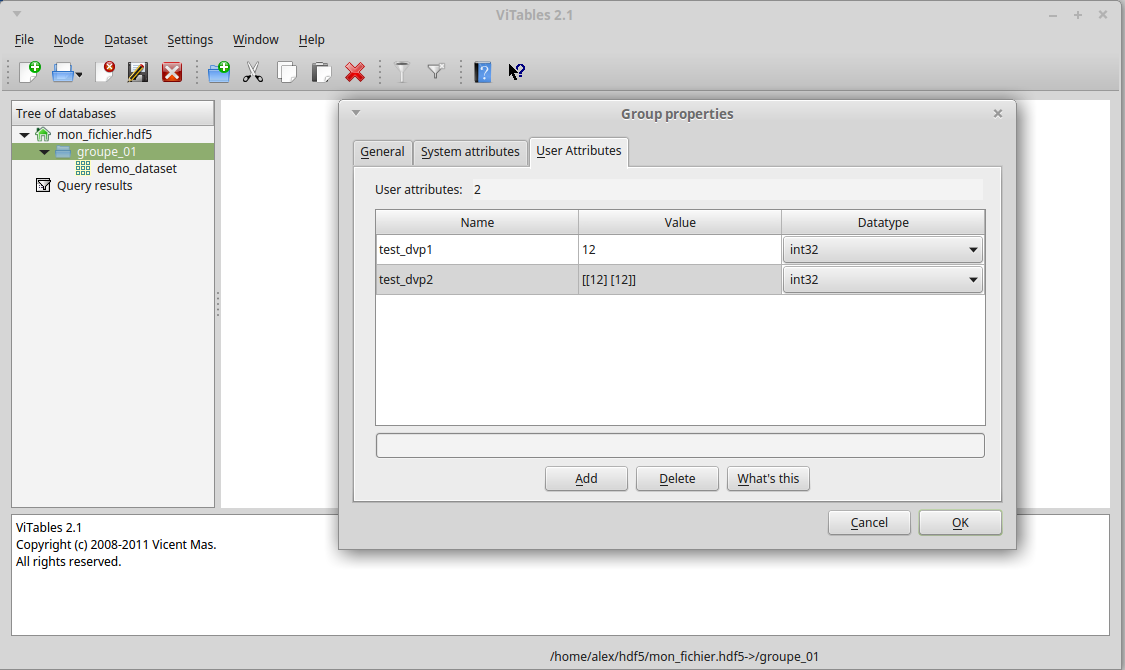
mon_fichier['/groupe_01'].attrs.create("test_dvp1", 12)
mon_fichier['/groupe_01'].attrs.create("test_dvp2",np.array([[12], [12]]))
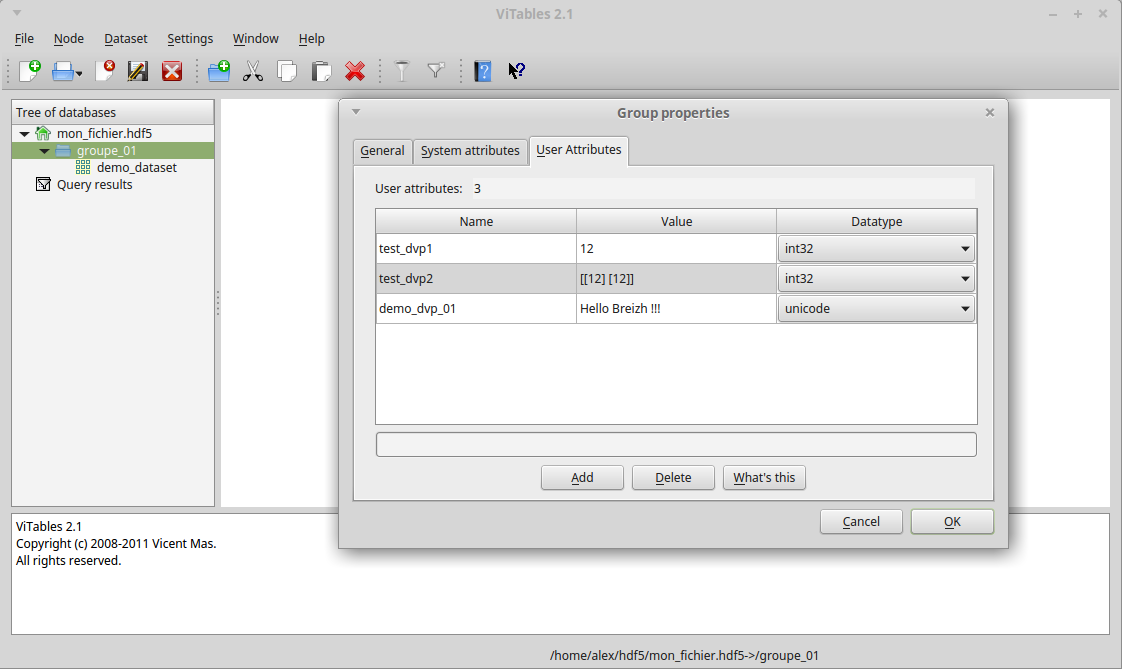
Veuillez noter qu'il est également tout à fait possible de passer par le dictionnaire « attrs » afin de se simplifier la vie. Il ne vous sera cependant possible que de créer des attributs avec des valeurs basiques, h5py se chargeant de définir automatiquement les paramètres « shape » et « dtype ».
mon_fichier['/groupe_01'].attrs['demo_dvp_01'] = 'Hello World !!!'

S'agissant d'attributs, cette dernière méthode est celle à privilégier, et que vous utiliserez le plus souvent, sauf cas spécifiques.
Côté modifications, elles sont quelque peu limitées. En effet, seule la valeur peut être modifiée, via la méthode « modify », ou via l'utilisation du dictionnaire « attrs ».
mon_fichier['/groupe_01'].modify('demo_dvp_01', 'Hello Breizh !!!')
mon_fichier['/groupe_01'].attrs['demo_dvp_01'] = 'Hello Breizh !!!'
III-E-2. Accès▲
Il existe deux principales façons d'avoir accès à un attribut.
La première méthode consiste à utiliser le dictionnaires « attrs » :
mon_fichier['/groupe_01'].attrs['demo_dvp_01']
La seconde, consiste à utiliser la méthode « get ». En effet, la première procédure, sous-entend que vous sachiez que l'attribut existe bien. Mais ce pourrait bien ne pas être le cas. La méthode « get » prendra une valeur par défaut qui vous sera renvoyée si l'attribut demandé n'existe pas.
Value = mon_fichier['/groupe_01'].get('demo_dvp', 'Cet attribut est inexistant.')
III-E-3. Suppression▲
La suppression se fait de même que pour l'élément d'un dictionnaire standard :
2.
3.
4.
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
del mon_fichier['/groupe_01'].attrs['demo_dvp_01']
III-E-4. Connaître la liste des attributs disponibles▲
En tant que dictionnaire, « attrs » vous autorise à connaître les clés disponibles, et donc à avoir accès à la liste d'attributs du groupe ou du dataset. Ainsi, il est aisé de faire :
2.
3.
4.
5.
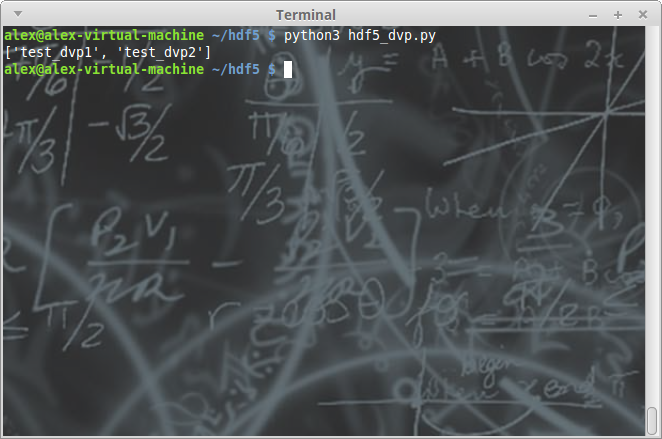
import h5py
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
liste_attributs = [key for key in mon_fichier['/groupe_01'].attrs.keys()]
print(liste_attributs)
Des modification ayant eu lieu récemment, en 2016, dans le stockage des données, votre version de h5py peut temporairement être incapable de lire les attributs systèmes. Plusieurs bogues sont ouverts à ce sujet depuis le printemps (exemple). Afin de ne pas récupérer ces attributs systèmes, il vous suffit d'utiliser les lignes de code suivantes :
liste_attributs = [key for key in mon_fichier['/groupe_01'].keys()]
III-F. Exemple de l'utilité du format▲
En quelque sorte « base de données » orientée purement numérique, ce format autorise le traitement massif des informations qui y sont stockées, permettant ainsi un gain de temps énorme, et en même temps, un accès aisé aux données.
La manipulation de matrice de grande taille demandant beaucoup de ressources, il se peut donc que l'exemple ne fonctionne pas chez vous. Dans ce cas je vous invite à diminuer la taille de la matrice.
Pour cet exemple, la première chose que nous allons faire est de créer une matrice numpy de « 1 » de 10 000 par 10 000 (soit 100 000 000 de données potentielles à traiter). On enregistrera alors cette matrice au format hdf5. On effectuera ensuite un traitement de masse, dans ce fichier sur une partie des données.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
import h5py
import time
import numpy as np
# Création d'une matrice
mon_tableau = np.ones((10000, 10000))
# création du fichier hdf5
mon_fichier = h5py.File('./mon_fichier.hdf5', 'a')
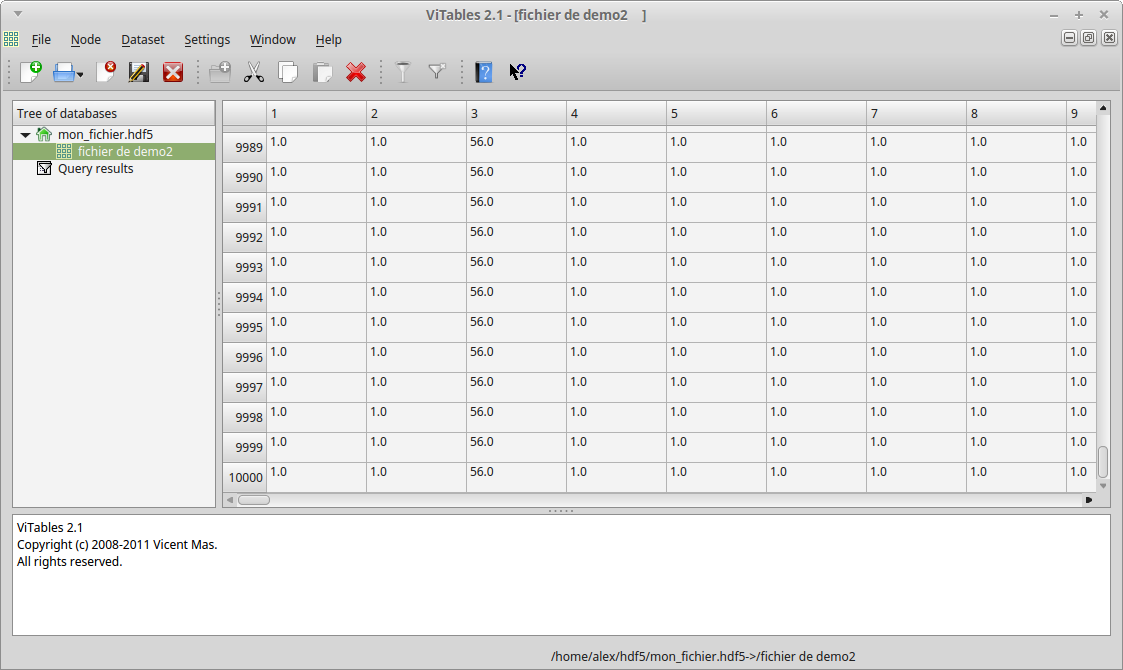
mon_dataset = mon_fichier.create_dataset("fichier de demo2", data=mon_tableau)
mon_fichier.flush()
# Maintenant les données numériques sont aisément accessible
start = time.time()
mon_dataset[:, 2] = 56 * mon_dataset[:, 3]
end = time.time()
print("10 000 données modifiées en {} secondes".format(end - start))
mon_fichier.close()
Comme on peux le constater, les données sont traitées très rapidement, et néanmoins disponibles dans un fichier unique aisément transmissible.
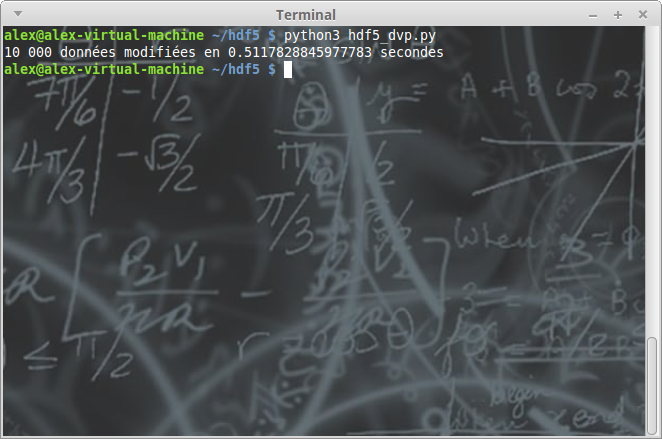
Un rapide coup d'œil aux caractéristiques du fichier vous apprendra que malgré la rapidité constatée sur la manipulation du fichier, il n'en pèse pas moins plus de 750 Mo.
IV. Conclusion▲
Comme nous venons de le voir, le format HDF5 est extrêmement adapté au traitement massif de données numériques.
Sous Python, son intégration est excellente, et la manipulation de données aisée grâce à NumPy.
Bien que ce tutoriel n'en soit qu'une introduction, j'espère néanmoins que la puissance de ce format vous permettra à l'avenir d'optimiser certains de vos développements logiciels.
